

Elixir和Phoenix是2022年Web应用程序的绝佳选择
- admin
- 13 Dec 2023
如何在 2022 年为应用选择最佳的 Web 编程语言和框架?这是可能吗?我相信是的,在这篇博文中,我将尝试说服您为什么 Elixir 和 Phoenix 是您正在寻找的完美组合。 ## Elixir: 生产力等于更少的成本 生产力仍然是编程语言的一个被大大低估的特性。一般来说,市场上的大多数应用程序都必须实现一些业务目标,众所周知,我们产生的成本越少
Read More如果您最近一直在关注 Twitter,您可能已经看到有关 Phoenix Web 框架可以处理的并发连接数的显著增加的文字。这篇文章记录了一些用于执行基准测试的技术。
几周前,我试图对连接数进行基准测试,并设法在我的本地计算机上获得 1k 个连接。我对这个数字不太确信,所以我在 IRC 上发帖,看看是否有人对 Phoenix channels 进行了基准测试。事实证明他们没有,但核心团队的一些成员认为我提供的 1k 数字非常低。这就是本次旅程的开始。
要对同时打开的 Web 套接字的数量进行基准测试,首先需要一个 Phoenix 应用程序来接受这些套接字。对于这些测试,我们使用了Gazler/phoenix_chat_example提供的chrismccord/phoenix_chat_application的略微修改版本- 主要区别在于:
大多数这些测试都是在Rackspace 15 GB I/O v1服务器上进行的——这些机器有 15GB RAM 和 4 个内核。Rackspace让我们免费使用其中 3 台服务器进行基准测试。他们还让我们使用具有 128GB RAM 并在 htop 中显示 40 个内核的OnMetal I/O服务器 。
需要进行的另一项更改是删除check_origin–conf/prod.exs,这意味着无论使用的 IP 地址/主机名如何,都可以连接应用程序。
要启动服务器,先git clone然后运行:
您可以通过访问YOUR_IP_ADDRESS:4000来验证是否有效。
为了运行客户端,我们使用了Tsung。Tsung 是一个开源分布式负载测试工具,可以轻松地对 websocket(以及许多其他协议)进行压力测试。
分布式的Tsung 工作方式是使用主机名。在我们的示例中,第一台机器被称为“phoenix1”,是在/etc/hosts进行的ip 分配。其他机器“phoenix2”和“phoenix3”也同样.
在与 Phoenix 应用程序不同的机器上运行客户端以进行基准测试非常重要。如果两者都在同一台机器上运行,结果将不是真实的表示。
Tsung 使用 XML 文件进行配置。您可以阅读文档进行配置。这是我们使用的配置文件(但是数字已经降低以反映这里的客户端数量,对于我们更大的测试,我们使用了 43 个客户端)。它每秒启动 1k 个连接,最多可达 100k 个连接。对于每个连接,它都会打开一个 websocket,加入“rooms:lobby”主题,然后休眠 30000 秒。
我们使用了较长的睡眠时间,因为我们希望保持连接打开,以查看在所有客户端连接后应用程序的响应速度。我们将手动停止测试,而不是关闭配置中的 websockets(您可以使用type="disconnect")。
<?xml version="1.0"?>
<!DOCTYPE tsung SYSTEM "/user/share/tsung/tsung-1.0.dtd">
<tsung loglevel="debug" version="1.0">
<clients>
<client host="phoenix1" cpu="4" use_controller_vm="false" maxusers="64000" />
<client host="phoenix2" cpu="4" use_controller_vm="false" maxusers="64000" />
<client host="phoenix3" cpu="4" use_controller_vm="false" maxusers="64000" />
</clients>
<servers>
<server host="server_ip_address" port="4000" type="tcp" />
</servers>
<load>
<arrivalphase phase="1" duration="100" unit="second">
<users maxnumber="100000" arrivalrate="1000" unit="second" />
</arrivalphase>
</load>
<options>
<option name="ports_range" min="1025" max="65535"/>
</options>
<sessions>
<session name="websocket" probability="100" type="ts_websocket">
<request>
<websocket type="connect" path="/socket/websocket"></websocket>
</request>
<request subst="true">
<websocket type="message">{"topic":"rooms:lobby", "event":"phx_join", "payload": {"user":"%%ts_user_server:get_unique_id%%"}, "ref":"1"}</websocket>
</request>
<for var="i" from="1" to="1000" incr="1">
<thinktime value="30"/>
</for>
</session>
</sessions>
</tsung>Tsung 在8091端口提供了一个 Web 界面,可用于监控测试状态。我们对这些测试真正感兴趣的唯一图表是并发用户数量。所以我第一次运行 Tsung 是在我自己的机器上, Tsung 和 Phoenix 聊天应用程序同时都在本地运行。这样做时,Tsung 经常会崩溃——发生这种情况时你看不到 Web 界面——这意味着没有图表可以显示,但它是一个不起眼的 1k 连接。
我远程设置了一台机器并再次尝试进行基准测试。这次我获得了 1k 连接,但至少 Tsung 没有崩溃。其原因是已达到系统范围的资源限制。为了验证这一点,我运行了ulimit -nwhich 返回1024,这可以解释为什么我只能获得 1k 个连接。
从这开始,使用了以下配置。这种配置将我们一路带到了 200 万个连接。
sysctl -w fs.file-max=12000500
sysctl -w fs.nr_open=20000500
ulimit -n 20000000
sysctl -w net.ipv4.tcp_mem='10000000 10000000 10000000'
sysctl -w net.ipv4.tcp_rmem='1024 4096 16384'
sysctl -w net.ipv4.tcp_wmem='1024 4096 16384'
sysctl -w net.core.rmem_max=16384
sysctl -w net.core.wmem_max=16384当 Chris McCord(Phoenix 的创建者)联系我告诉我 RackSpace 已经设置了一些实例供我们用于基准测试时,我一直在 IRC 中谈论 Tsung。我们必须使用以下配置文件设置 3 台服务器:https://gist.github.com/Gazler/c539b7ef443a6ea5a182
在我们启动并运行之后,我们将一台机器专用于 Phoenix,另外两台用于运行 Tsung。我们的第一个真正的基准测试以大约 27k 连接结束。
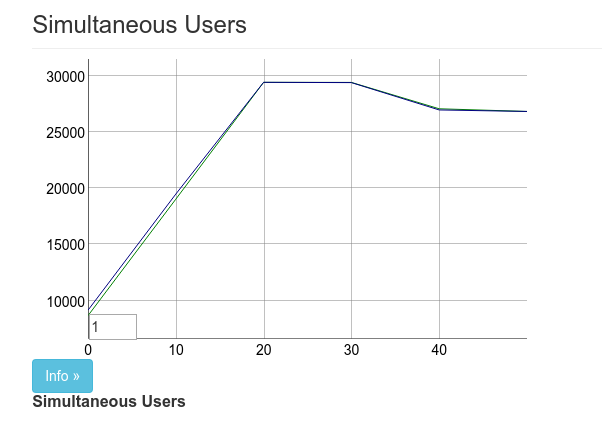
在上图中,图表上有两条线,顶部的线标记为“用户”,底部的线标记为“已连接”。用户根据到达率增加。对于大多数这些测试,我们使用每秒 1000 个用户的到达率。
结果一出来,José Valim 就提交了一次改进
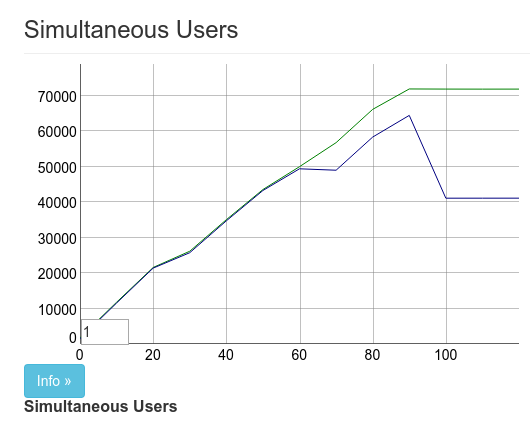
这是我们的第一次改进,这是一个很大的改进。从这里我们得到了大约 50k 的连接。
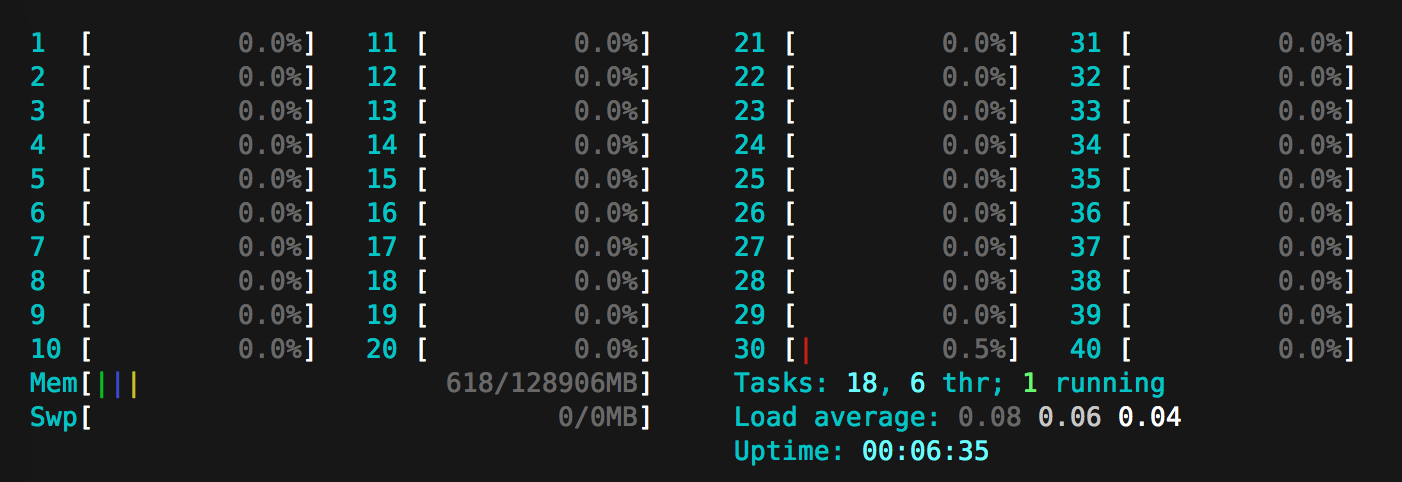
在我们的第一次改进之后,我们意识到我们是盲目的。如果有某种方式可以观察正在发生的事情的话就更好了。幸运的是,Erlang 附带了observer,它可以远程使用。我们使用 https://gist.github.com/pnc/9e957e17d4f9c6c81294 中的以下技术来打开remote observer。
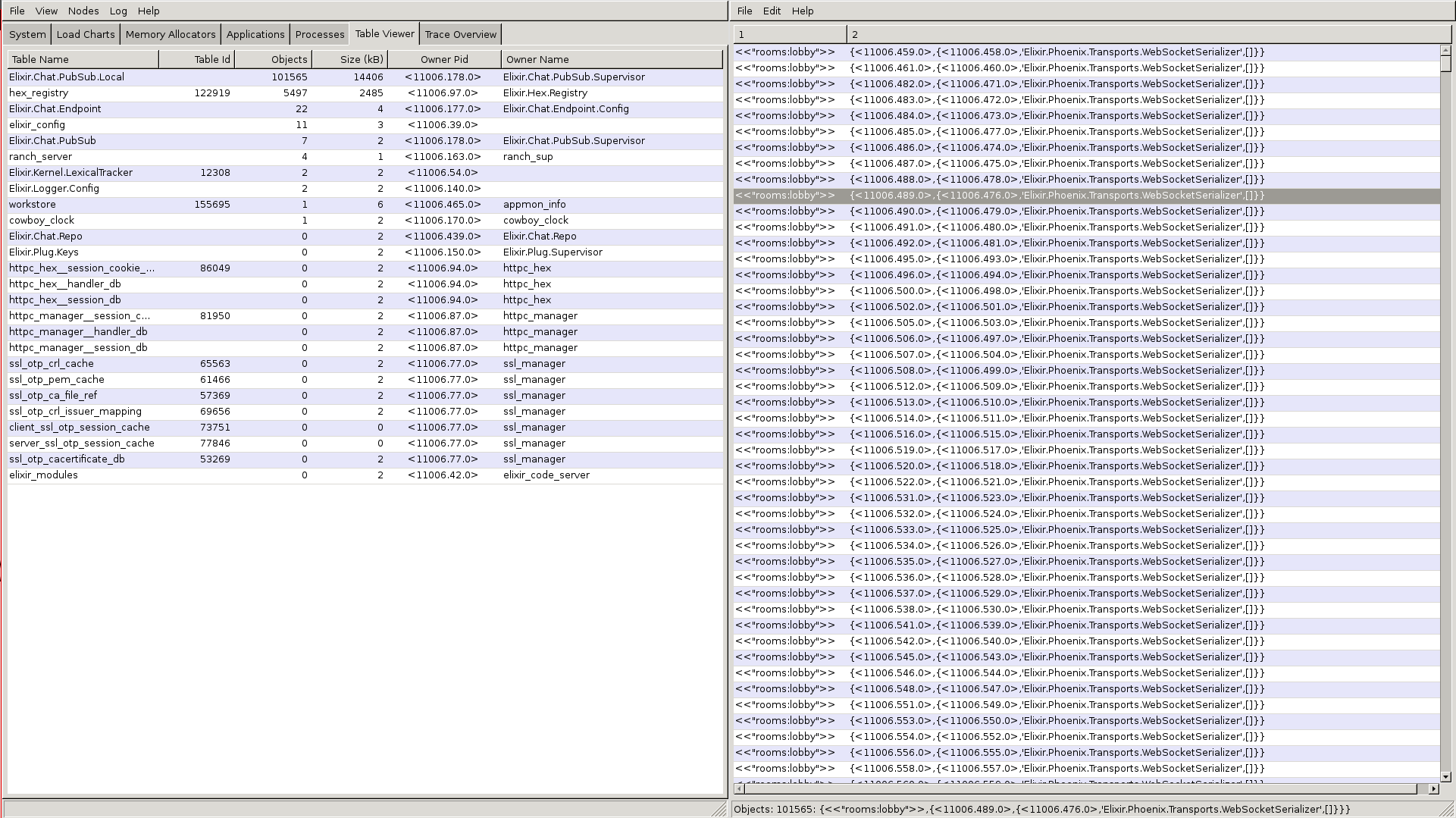
Chris 使用observer根据邮箱的大小对进程进行排序。:timer进程的邮箱中有大约 40k 条消息。这是因为 Phoenix 每 30 秒做一次心跳以确保客户端仍然连接。
幸运的是,Cowboy 已经解决了这个问题,所以在这次提交之后,结果看起来像:
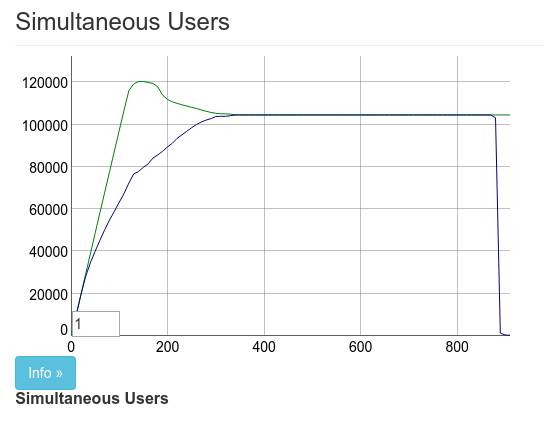
实际上,在这张图片中我使用observer杀死了 pubsub 主管进程,这解释了最后的 100k 连接的下降。这是第二次翻番的性能提升。测试中使用 2 台 Tsung 机器提供 100k 并发连接。
上图有两个问题。一是我们没有达到全部客户端数量(大约 15k 时进入超时状态),二是我们实际上只能为每个 Tsung 客户端生成 40k 到 60k 连接(每个 IP 地址存在技术上的上限)。对于 Chris 和我来说,这还是不够好。除非我们可以产生更多客户端负载,否则我们无法真正看到限制。
在这个阶段,RackSpace 给了我们内存 128GB 的服务器,所以我们实际上还有另一台机器可以使用,使用像 Tsung 客户端这样强大的软件而被限制在 60k 连接可能看起来很浪费,但总比机器闲置好!Chris 和我在我们之间设置了另外 5 个服务器,这是另外 30 万个可能的连接。
我们再次运行基准测试,我们获得了大约 33 万个连接的客户端。
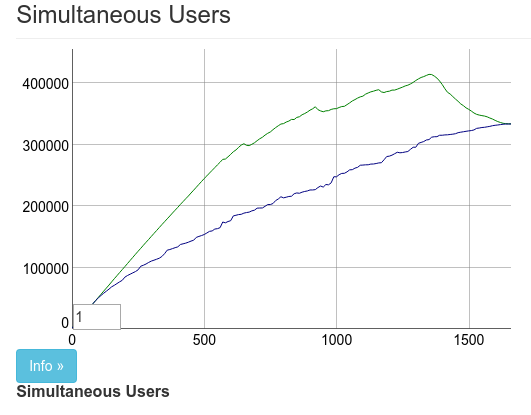
现在最大的问题是大约 70k 的连接并没有真正连接到机器上。我们不知道为什么。有可能是硬件问题。我们决定尝试在 128GB 机器上运行 Phoenix。这样达到我们的连接限制肯定不会有问题,对吧?
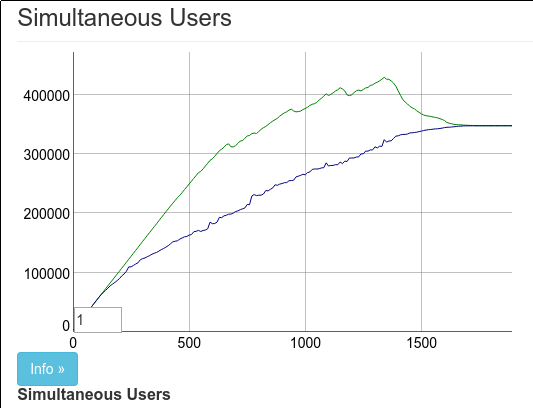
但结果是错误的。这里的结果与上面的结果几乎相同。克里斯和我认为 330k 也相当不错。克里斯在推特上发布了结果,我们称之为一个阶段性成果。
可以称之为已经达到了最大的channels数量:大约333k并发客户. 它耗尽了8台服务器的最大端口来进行推送,还剩下大约40%的内存,但是我们没有服务器了。
- Chris McCord (@chris_mccord) October 24, 2015
在达到 330k 并发客户并获得 2 次相当容易的性能提升后,我们不确定是否还会有更多相同幅度的性能提升。但是我们错了。当时我并没有意识到这一点,但我在Voice Layer的同事 Gabi Zuniga ( @gabiz )周末一直在研究这个问题。他的承诺给了我们迄今为止最好的性能提升。您可以在 pull request上看到差异。为方便起见,我也会在这里展示出来:
- ^local = :ets.new(local, [:bag, :named_table, :public,
+ ^local = :ets.new(local, [:duplicate_bag, :named_table, :public,这 10 个额外的字符使图表看起来像这样:
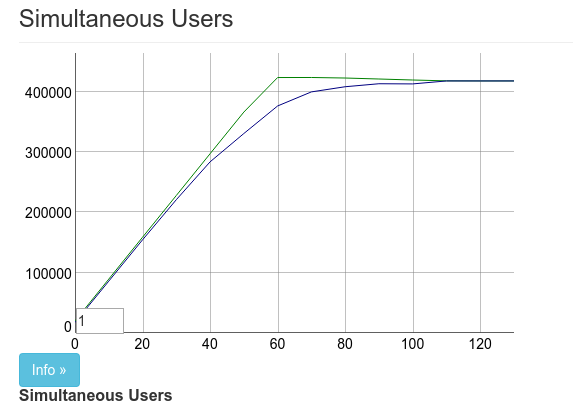
它不仅增加了并发连接的数量。它还使我们也可以将到达率提高 10 倍。这使得后续测试更快。
bag和 duplicate_bag之间的区别在于duplicate_bag允许同一个键有多个条目。由于每个套接字只能连接一次并且有一个 pid,因此使用重复包不会对我们造成任何问题。
这次测试在大约 450k 连接时达到最大值。此时 16GB 服务器的内存不足。我们现在已经准备好真正测试更大的服务器了。
在phoenix channels benchmark上声称结束为时尚早,有了 @gabiz 提供的优化,我们已经在4核/15G的服务器上获得了450k并发客户的成绩。
— Chris McCord (@chris_mccord) October 25, 2015
Justin Schneck ( @mobileoverlord ) 在 IRC 上告诉我们,他和他的公司Live Help Now将在 RackSpace 上设置一些额外的服务器供我们使用。准确地说,还有 45 台额外的服务器。
我们设置了几台机器,并将 Tsung 的阈值设置为 100 万个连接。这时 128GB 机器轻松实现的新里程碑:
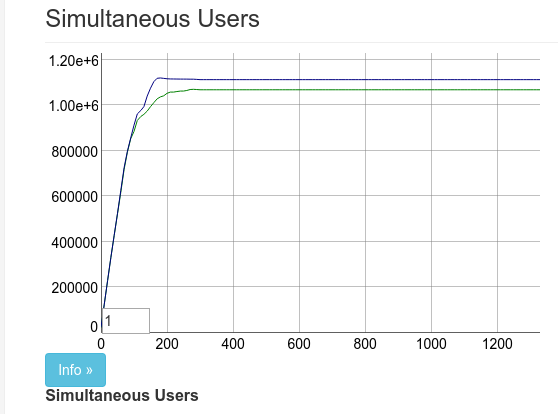
当 Justin 完成所有 45 个服务器的设置时,我们确信有 200 万个连接是可能的。不幸的是,事实并非如此。仅在 130 万个连接处开始出现一个新的瓶颈!
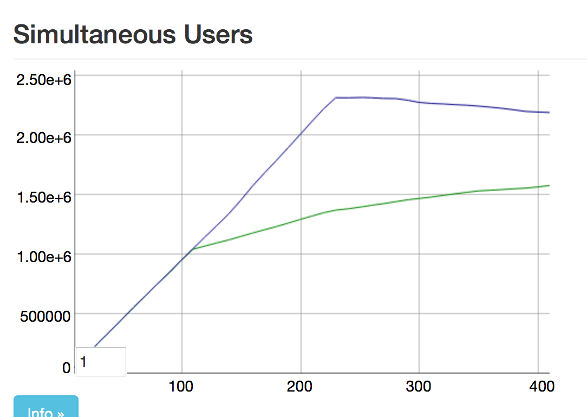
就是这样。1.3M 连接就足够了,对吧?错误的。在我们达到 130 万订阅者的同时,我们在请求订阅单个 pubsub 服务器时开始定期超时。我们还注意到广播时间大幅增加,向所有订阅者广播的时间超过 5 秒。
Justin 对物联网感兴趣,并想看看我们是否可以优化 1.3+M 订阅者的广播,因为他看到了这些级别的真实用例。他的想法是通过分块订阅者和并行化广播工作来分割广播。我们尝试了这个想法,它将广播时间缩短到 1-2 秒。但是,我们仍然有那些讨厌的订阅超时。我们处于单个 pubsub 服务器和单个 ets 表的限制。所以 Chris 开始着手将 pubsub 服务器池化,我们意识到我们可以将 Justin 的广播分片与 pubsub 服务器池和 ets 表结合起来。因此,我们通过订阅者 pid 将其分片到一个 pubsub 服务器池中,每个服务器都管理自己的 ets 表。这让我们可以在没有超时的情况下达到 200 万订阅者并保持 1s 广播。代码改变正在进行中,这个提交在合并到 master 之前正在被完善。
所以你现在有了200万连接!每次我们认为不再需要进行优化时,就会提出另一个想法,从而大幅提高性能。
200万是我们满意的数字。但是,我们并没有完全使用机器,我们还没有做出任何努力来减少每个套接字处理程序的内存使用量。此外,我们还将执行更多基准测试。这组特定的基准专门围绕同时打开的套接字数量设置。拥有 200 万用户的聊天室非常棒,尤其是在消息传播得如此之快的情况下。不过,这不是典型的用例。以下是一些未来的基准测试想法:
在此基准测试中发现的改进将在即将发布的 Phoenix 版本中提供。密切关注未来基准测试的信息,Phoenix 将继续推动现代网络的边界。
如何在 2022 年为应用选择最佳的 Web 编程语言和框架?这是可能吗?我相信是的,在这篇博文中,我将尝试说服您为什么 Elixir 和 Phoenix 是您正在寻找的完美组合。 ## Elixir: 生产力等于更少的成本 生产力仍然是编程语言的一个被大大低估的特性。一般来说,市场上的大多数应用程序都必须实现一些业务目标,众所周知,我们产生的成本越少
Read More如果您最近一直在关注 Twitter,您可能已经看到有关 Phoenix Web 框架可以处理的并发连接数的显著增加的文字。这篇文章记录了一些用于执行基准测试的技术。 ## 它是如何开始的 几周前,我试图对连接数进行基准测试,并设法在我的本地计算机上获得 1k 个连接。我对这个数字不太确信,所以我在 IRC 上发帖,看看是否有人对 Phoenix cha
Read More